压缩主要分为以下 4 种技术
- 剪枝(Pruning):移除模型中不必要或多余的组件,比如参数,以使模型更加高效;
- 知识蒸馏(Knowledge Distillation):从一个复杂的模型(称为教师模型)向一个简化的模型(称为学生模型)转移知识来实现;
- 量化(Quantization):将传统的表示方法中的浮点数转换为整数或其他离散形式,以减轻深度学习模型的存储和计算负担;
- 低秩分解(Low-Rank Factorization):低秩分解旨在通过将给定的权重矩阵分解成两个或多个较小维度的矩阵,从而对其进行近似。
剪枝(Pruning)
剪枝主要分为:
- 非结构化剪枝:指移除个别参数,而不考虑整体网络结构。这种方法通过将低于阈值的参数置零的方式对个别权重或神经元进行处理。它会导致特定的参数被移除,模型出现不规则的稀疏结构。并且这种不规则性需要专门的压缩技术来存储和计算被剪枝的模型。此外,非结构化剪枝通常需要对 LLM 进行大量的再训练以恢复准确性,训练成本高。
- 结构化剪枝:根据预定义规则移除连接或分层结构,同时保持整体网络结构。这种方法一次性地针对整组权重,优势在于降低模型复杂性和内存使用,同时保持整体的 LLM 结构完整。
知识蒸馏(Knowledge Distillation)
知识蒸馏(KD),也被称为教师-学生神经网络学习算法,是一种有价值的机器学习技术,旨在提高模型性能和泛化能力。 核心思想是将教师模型的综合知识转化为更精简、更有效的表示。 根据是否将 LLM 的涌现能力(EA)提炼成小语言模型(SLM)来对蒸馏方法进行分类:标准知识蒸馏 和 基于 EA 的知识蒸馏。
当一个复杂系统由很多微小个体构成,这些微小个体凑到一起,相互作用,当数量足够多时,在宏观层面上展现出微观个体无法解释的特殊现象,就可以称之为“涌现现象”。
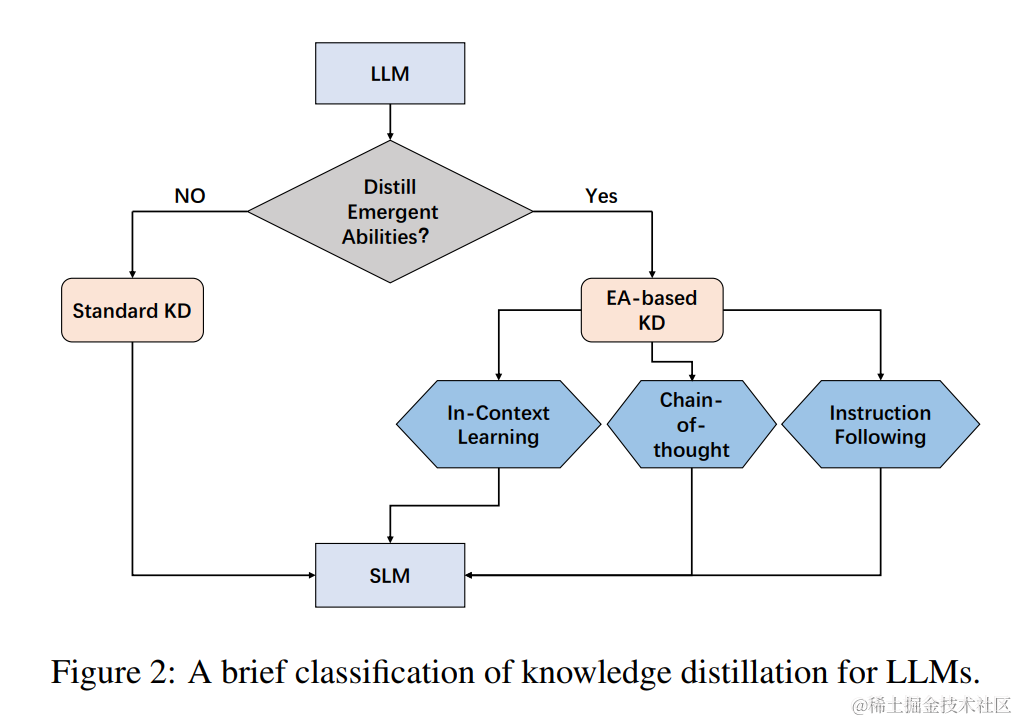
标准知识蒸馏
Standard KD 旨在使学生模型学习 LLM 所拥有的常见知识,如输出分布和特征信息。这种方法类似于传统的 KD,但区别在于教师模型是 LLM。 比如:MINILLM 和 GKD。
我的理解是使用构建好的数据集(但是没有进行任务的拆分),输入到 LLM 当中,然后得到的输出,用来训练 SLM。 loss 函数是输出的 KL 散度,然后进行更新,有点类似回归。
基于 EA 的知识蒸馏
基于 EA 的 KD 不仅仅迁移 LLM 的常识,还包括蒸馏他们的涌现能力。
与 BERT(330M)和 GPT-2(1.5B)等较小模型相比,GPT-3(175B)和 PaLM(540B)等 LLM 展示了独特的行为。 这些LLM在处理复杂的任务时表现出令人惊讶的能力,称为“涌现能力”。 涌现能力包含三个方面,包括上下文学习 (ICL)、思维链 (CoT) 和指令遵循 (IF)。 如图三所示,它提供了基于 EA 的知识蒸馏概念的简明表示。
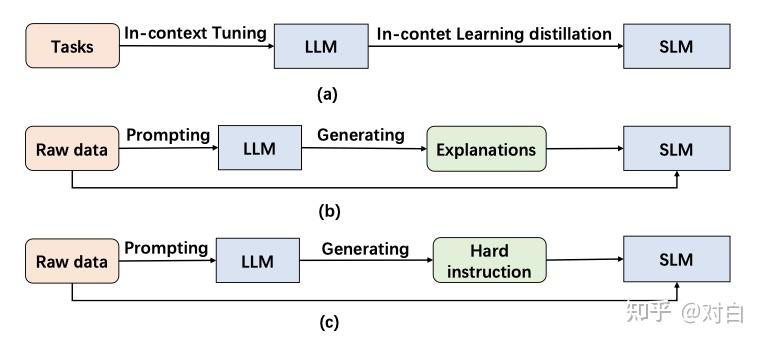
实际上就是构建不同类型的 prompt,输入到 LLM 中,构建出新的数据集,然后用来训练小模型
- ICL 采用结构化自然语言提示,其中包含任务描述以及可能的一些任务示例作为演示
- CoT 采用了不同的方法,它将中间推理步骤(可以导致最终输出)合并到提示中,而不是使用简单的输入输出对。
- IF 致力于仅基于阅读任务描述来增强语言模型执行新任务的能力,而不依赖于少数样本。通过使用一系列以指令表示的任务进行微调,语言模型展示了准确执行以前未见过的指令中描述的任务的能力。
量化(Quantization)
根据应用量化压缩模型的阶段,可以将模型量化分为:
- 量化感知训练(Quantization Aware Training, QAT):在模型训练过程中加入伪量化算子,通过训练时统计输入输出的数据范围可以提升量化后模型的精度,适用于对模型精度要求较高的场景;其量化目标无缝地集成到模型的训练过程中。这种方法使LLM在训练过程中适应低精度表示,增强其处理由量化引起的精度损失的能力。这种适应旨在量化过程之后保持更高性能。
- 量化感知微调(Quantization-Aware Fine-tuning,QAF):在微调过程中对LLM进行量化。主要目标是确保经过微调的LLM在量化为较低位宽后仍保持性能。通过将量化感知整合到微调中,以在模型压缩和保持性能之间取得平衡。
- 训练后量化(Post Training Quantization, PTQ):在LLM训练完成后对其参数进行量化,只需要少量校准数据,适用于追求高易用性和缺乏训练资源的场景。主要目标是减少LLM的存储和计算复杂性,而无需对LLM架构进行修改或进行重新训练。PTQ的主要优势在于其简单性和高效性。但PTQ可能会在量化过程中引入一定程度的精度损失。
低秩分解(Low-Rank Factorization)
低秩分解的基本思想: 将原来大的权重矩阵分解成多个小的矩阵,用低秩矩阵近似原有权重矩阵。 这样可以大大降低模型分解之后的计算量,常常用于神经网络模型分解。 ![]()
Reference
- 大模型压缩首篇综述来啦~:https://zhuanlan.zhihu.com/p/652434165
- 大模型知识蒸馏概述:https://zhuanlan.zhihu.com/p/659943824
- 大模型量化概述:https://zhuanlan.zhihu.com/p/662881352
- 模型压缩之模型分解篇:SVD分解,CP分解和Tucker分解:https://zhuanlan.zhihu.com/p/490455377