经过预训练,LLM 此时已经掌握了大量知识,然而此时它只会无脑地词语接龙,还不会与人聊天,需要进行大模型参数微调,使得模型能够正常对话。
从参数更新上分为 全参数微调(Full Fine-Tuning)和 PEFT(Parameter-Efficient Fine-Tuning),其中 PEFT 只对部分参数进行更新。
从训练方法上来看,分为 监督式微调 SFT(Supervised Fine Tuning) 和 基于强化学习(Reinforcement Learning,RL)的微调,包含
- 基于人类反馈的强化学习微调 RLHF (Reinforcement Learning with Human Feedback)
- 基于 AI 反馈的强化学习微调 RLAIF (Reinforcement Learning with AI Feedback)。
全参数微调(Full Fine-Tuning)
实际上和预训练需要的成本一致,成本太高。
PEFT(Parameter-Efficient Fine-Tuning)
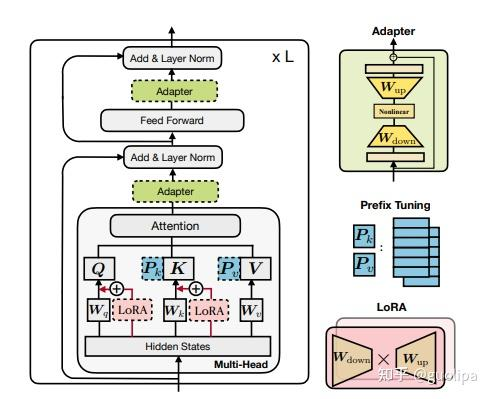
如下图所示,PEFT 方法可以分为三类,不同的方法对 PLM 的不同部分进行下游任务的适配:
- Prefix/Prompt-Tuning:在模型的输入或隐层添加 k 个额外可训练的前缀 tokens(这些前缀是连续的伪 tokens,不对应真实的 tokens),只训练这些前缀参数;
- Adapter-Tuning:将较小的神经网络层或模块插入预训练模型的每一层,这些新插入的神经模块称为 adapter(适配器),下游任务微调时也只训练这些适配器参数;
- LoRA:通过学习小参数的低秩矩阵来近似模型权重矩阵 W 的参数更新,训练时只优化低秩矩阵参数。
LoRA(Low-Rank Adaptation)
LoRA 基本思想:
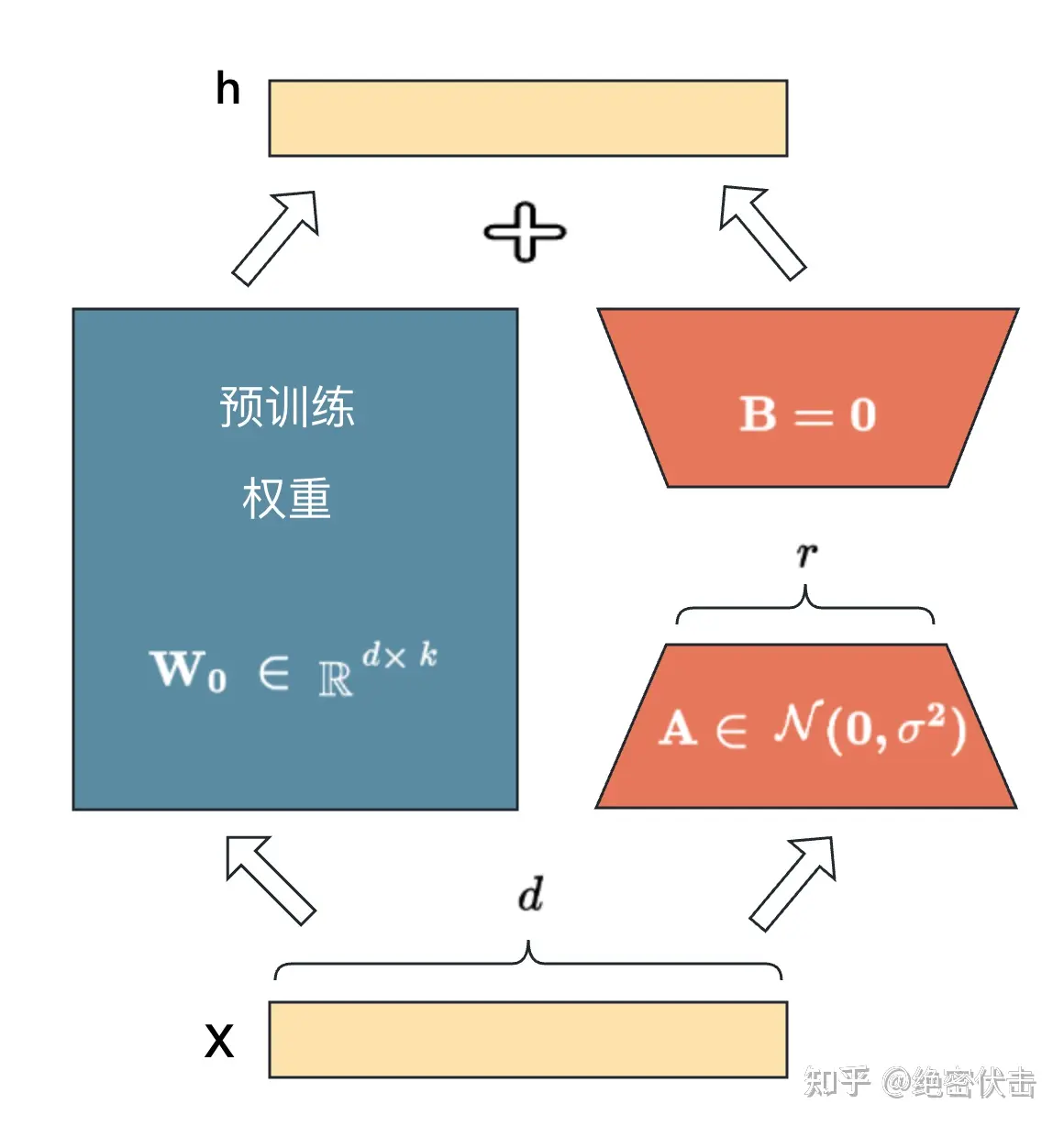
- 在原始 PLM (Pre-trained Language Model) 旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的 intrinsic rank(本征秩,最能体现数据本质的维度(特征)数目)。
- 训练的时候固定 PLM 的参数,只训练降维矩阵 A 与升维矩阵 B 。而模型的输入输出维度不变,输出时将 BA 与 PLM 的参数叠加。
- 用随机高斯分布初始化 A ,用 0 矩阵初始化 B ,保证训练的开始此旁路矩阵依然是 0 矩阵。
LoRA 需要更新的参数远小于整个模型的参数,甚至小于 PLM 的 0.01 %。
前向推导公式为: 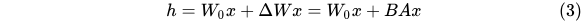
SFT
SFT 实际上和预训练一致,只是使用的数据集不一样了,并且一般是固定格式的 prompt。
minimind 作者对 匠数大模型SFT数据集 和 Magpie-SFT数据集 进行了数据清洗(只保留中文字符占比高的内容),筛选长度<512的对话,得到sft_mini_512.jsonl(~1.2GB)。 所有sft文件 sft_X.jsonl 数据格式均为
{
"conversations": [
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!"},
{"role": "user", "content": "再见"},
{"role": "assistant", "content": "再见!"}
]
}RL
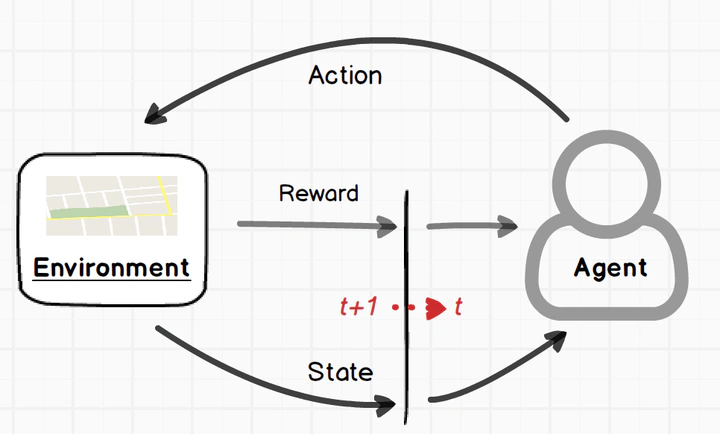
强化学习是一种机器学习方法,智能体通过与环境交互,尝试不同的行为策略,根据获得的奖励信号不断优化自己的决策,以最大化长期累积奖励。 其核心思想是“试错学习”,类似于人类通过实践和反馈来改进行为。
优化目标是通过选择策略来最大化累积奖励。 具体来说,智能体的目标是寻找一个最优策略 pi*,使得它在各个状态下的累积回报最大。 形式上,可以用价值函数(Value Function)或动作价值函数(Q函数)来表示。
在 NLP 中的 RL 简要如下所示 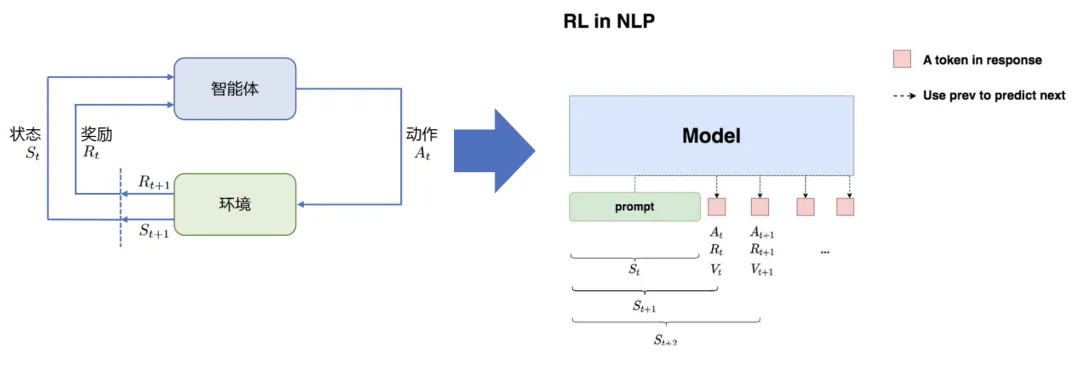
状态S:输入 prompt
动作A:输出 response(即 LLM 输出下一个token)
奖励R:根据 prompt + response 进行奖励模型打分
整体目标:给定 prompt,调整 policy,生成符合人类喜好的response
RLHF(RM + PPO)
RLHF 中有三种数据集,分别是:
- 偏好数据集:用来训练奖励模型。
- 提示数据集:在 PPO 流程中用来训练 LLM。
- 评估数据集:用来评估RLHF的效果。
RM 是监督学习,令奖励模型输出一个标量评分 R 回答:
对同一问题的回答 A 和回答 B,若人类偏好 A,则训练目标是 R(A) > R(B),即回答 A 的奖励大于回答 B 的奖励。
然后就是常规的使用 PPO 进行训练的流程。
DPO
DPO 不是传统意义上的强化学习,但它与强化学习有一定的关联,并且可以被视为一种替代方法来解决某些强化学习问题。 其优化过程关注于最大化偏好数据下策略的表现,通过对比学习等技术直接在策略上进行优化,避免了额外的奖励函数建模步骤。
现有 RLHF 方法通常会首先使用一个奖励模型(Reward Model)来拟合一个包含提示(Prompt)和人类对响应对(Response Pair)偏好的数据集,然后通过强化学习找到一个能够最大化该奖励模型的策略(Policy)。 相比之下,DPO 直接以简单的分类目标优化最能满足偏好的策略,通过拟合一个隐式奖励模型,其对应的最优策略可以以闭式形式(Closed Form)提取出来。
DPO 的基本原理:增加偏好样本的对数概率与减小非偏好样本响应的对数概率。 它结合了动态加权机制,以避免仅使用概率比目标时遇到的模型退化问题。 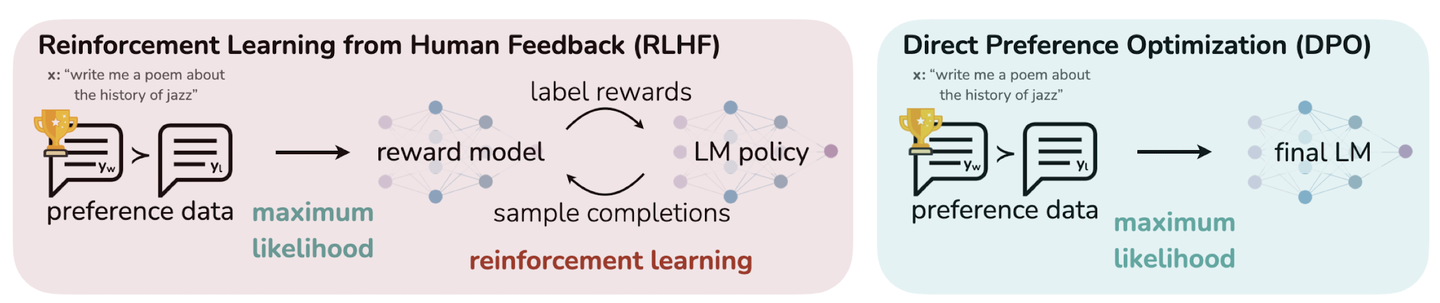
DPO 损失函数,参考: 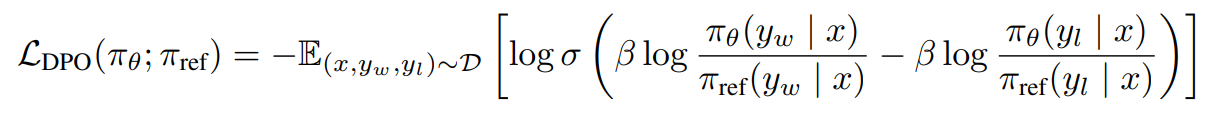
GRPO
GRPO 是对 PPO 的一种改进版本,属于online RL。它通过暴力采样求均值的方式替代了 PPO 中的 Critic Model。 同时保留了PPO中的重要性采样和裁剪机制。GRPO中冻结了Ref和RM 2个模型,仅需要训练Policy Model。 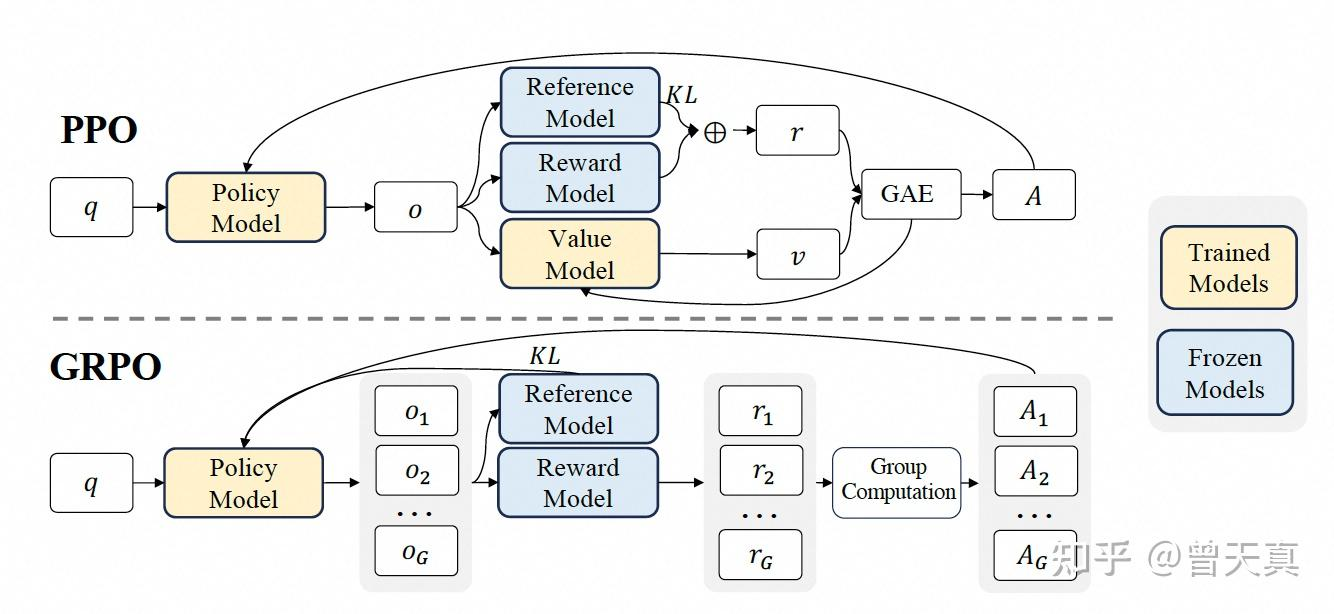
GRPO 的目标函数: 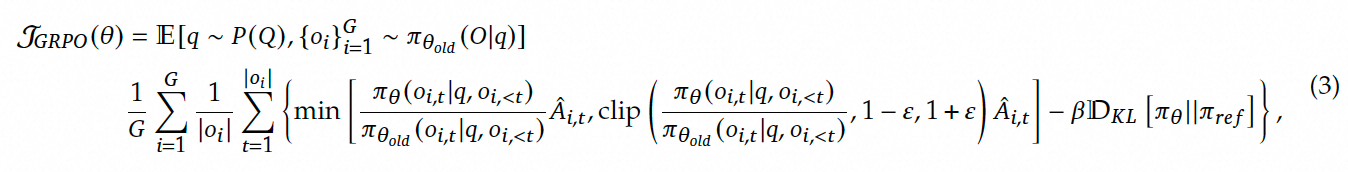
算法: 
Reference
- 炼石成丹:大语言模型微调实战系列(二)模型微调篇:https://aws.amazon.com/cn/blogs/china/practical-series-on-fine-tuning-large-language-models-part-two/
- 通俗解读大模型微调(Fine Tuning):https://zhuanlan.zhihu.com/p/650287173
- 大模型参数高效微调(PEFT):https://zhuanlan.zhihu.com/p/621700272
- LORA:大模型轻量级微调:https://www.zhihu.com/tardis/zm/art/623543497
- 大模型高效微调-LoRA原理详解和训练过程深入分析:https://zhuanlan.zhihu.com/p/702629428
- 大模型中的强化学习:https://zhuanlan.zhihu.com/p/693582342
- DPO: Direct Preference Optimization 论文解读及代码实践:https://zhuanlan.zhihu.com/p/642569664
- 详解DeepSeek-R1核心强化学习算法:GRPO:https://zhuanlan.zhihu.com/p/21046265072